
真的很久没写博客了,一直提不起兴趣,总觉得写一些代码如何写,工具如何用,过一阵子就不是很有用了,所以想写一些自己的心得体会,但又很难总结成文章。这几天突然间想通了一些,也许我是时候抛开前端这个枷锁了,今天我们来谈谈敏捷开发的结对编程。
想当年(然而并没有几年)刚来到ThoughtWorks的时候,除了英语,我最不适应的就是pair,即结对编程。因为刚上项目的我只能跟着结对对象的思维走,即使我思路正确了也无非是在我的结对对象写的代码上印证了一下,少有的贡献就是不时的提醒他一下typo之类无关紧要的错误。然后当我拿到键盘时,还是因为信息的不对等,我无法在全局层面上做出贡献,因为我必须非常熟悉整个项目才能说服我的pair,修改一些架构上的代码,否则只能改进一些细节上的代码片段。这种毫无创造性的工作方式让我昏昏欲睡,说好的挑战,困难,压力呢?我感到了一种可有可无的迷茫。
不同的Pair类型
接着我开始了没有什么意义的强势逆袭之路,每天回家之后熟悉代码,有时半夜还在写代码,当然没有结对编程的我只能写完checkout,仅仅是为了熟悉代码库。因为我感受到对代码库的熟悉程度某种程度上决定了结对编程时的话语权。
后来终于在第四个项目上,我始终掌握了代码库最全的信息,至少在团队内是这样的。虽然进度压力仍然不小,但我们还是装模作样的进行了结对编程,这次是从项目开始我就加入了,如此,我在结对时的角色发生了变化,大部分是在给我的结对对象传授知识。慢慢的我发现我总是在写代码,我的结对对象只负责看,这样好像不太对,为什么不对呢?那时我并不知道原因,但我试着改变了风格,让对方来写,我提建议。当然有时候遇到复杂的问题,我也会急不可耐的把键盘抢过来快速搞定它,再讲解一番,接着在code review的时候发现我的结对对象并没有听懂我为什么要这么做,然而这是另外一个问题了,暂且不谈。
其实上面提到的就是几种不同类型的结对方式:
Backseat Driver
就是改变风格的我,让对方写,但还是我drive,这样至少一个在写,一个在思考,交流还是比较多的。
Keyboard Grabber
就是急不可闹抢过键盘飞快写起来的我,通常是因为双方技术和信息量差距较大,而较高一方没有耐心了。
Silent Sleeper
也就是上面提到的昏昏欲睡的我,这一般是另一方太快,而且没有说清楚自己的逻辑导致的,当然也有可能是你思维太慢,比如代码库的信息量太少。
Sprinter
在第一个项目我刚刚上手写的时候,大概我的结对对象眼中我就是个sprinter吧,总是想从架构上做一些重构,但又不会TDD,所以刚有个念头就被喊stop了。
结对编程究竟为了什么
简单来说,结对编程是为了交流并传播知识,还有避免陷入思维盲区,所以要让两个人一起写代码,沟通相互的不同,在从思维差异到相通的过程中找到更棒的解决方案,最终使团队中每个人都能达到共同智慧所能达到的最高境界——思维的并集。然而从我们决定结对编程开始,一直到最高境界是有很长一段路要走的。在磨合的过程中,这恰好又是四个类型:
- 高手写,新手看。
- 新手写,高手看。
- 两个高手相争。
- 两个新手入坑。
注意,这里的高手和新手只是指的相对而言,可能是对代码的信息量不同,也可能是技术方向不同导致的。
前面两种其实都是在传授知识,只不过一种是直接传授,一种是通过反馈来传授。这两种情况都是在团队成员所掌握的信息不平衡时所出现的,它们的目标都是最终达到每个人的知识都是一致的。
而后面两种才是项目中的常态,先让我们抛弃高手与新手这样的概念,只是两个水平和信息量相近的程序员进行结对编程。如果两人的思路差异比较大就会产生第三种情况,在某些技术点上产生分歧,然后挣的面红耳赤。最终可能是某人赢得了胜利,这样就失去了结对编程得意义,也浪费了另一个人的思维。也可能是在两边的妥协中产生了一个微妙的结果,这显然没有达到理想的状态,仅仅是思维的交集。如果两人的沟通渐入佳境,找到了和谐的思维交流方式,仍然要小心陷入第四种情况。
我们知道结对编程的好处之一是防止陷入思维盲区,因为一个人的思维是有限的,很容易忽略掉一些东西而不自知,俗话说得好,旁观者清,也是这个道理。但当两人的思维渐渐一致,有了默契之后还算两个思维吗?是不是也会存在思维盲区。如此看来结对编程的目标是让两个人思维一致的理想状态,而这种理想状态又会导致没有结对时思维盲区的问题,这就像是一个悖论,难道我们只能在即将到达理想状态的时候体验一下结对编程的好处?我渐渐的发现,肯定有哪里不对。
结对编程状态模型
既然两个人总在结对编程时会产生这样的问题,那我们就轮换着来,实际上很多项目就是这样做的,但通常我们会用一个小程序随意选择结对对象。看起来很科学,我们终于可以比较均匀的和其他人结对了,这样就不会和某个人变成同一个思维了。
然而问题就和bug一样总是层出不穷。如果在任务粒度比较粗,而人数又不多的时候,交换结对又变得很艰难,因为你做完了这个用户故事,另一对人可能才刚发现并开始着手解决问题,此时显然不适合更换,而你和你的结对对象也不可能干等着,依赖于另一对人当前用户故事的用户故事也没法做,于是经常出现某对结对一直在做某个部分的用户故事,然而我们只能祈祷两对结对刚好差不多同时做完。这某种程度上就是所谓的理想状态,两个人变成了一个人。
必须继续改进,所以我们让一个人待在用户故事上,另一个人交换。尝试了一阵子后,又有人觉得更换结对对象太频繁了,刚加入项目的新人还没来得及熟悉一个用户故事,又被换到另一个用户故事上了,最后变成了一个人在主导用户故事,另一个人始终旁观。这又变成了最初的状态,一个人做,另一个看,还是一个人的思维。
虽然问题很多,但我忽然间想到了一个模型,也许能把问题简化一下,如图: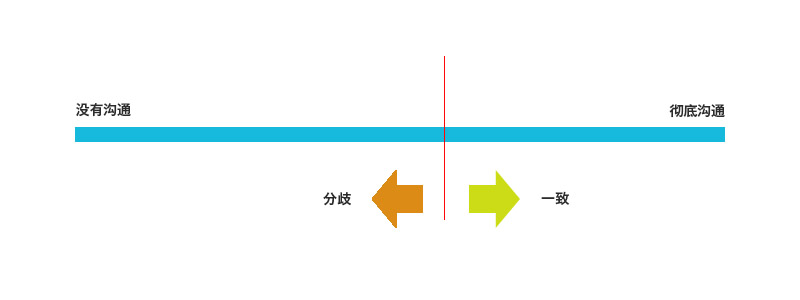
这条轴代表的是沟通交流的程度,可以称为结对编程的状态轴,而两个端点就是上面提及的问题的状态,没有沟通和彻底沟通都会形成单一思维,失去了结对编程的意义。在结对编程的过程中双方就会变得一致,往右边移动,如果有什么因素使得双方信息不对等或者知识不一致,就会产生分歧,往左边移动。中间的红线则代表了真正最佳的状态,有一定的沟通,但又不是一种思维,可以避免思维盲区。
现在问题就简单了,我们如何驱动一对结对对象向左或者向右,将状态维持在红线附近呢?
打碎你的结对
我认为必须改变我们的目标,否则两个人的目标一致总会达成彻底的沟通。而我们的目标就是完成用户故事解决问题,所以我想到了改变两人所分配的用户故事,也就是说你和你的结对对象将不再工作在同一张卡上。这听起来有点天方夜谭,如果两个人不工作在同一张卡上还算是结对编程吗?我认为只要两个人坐在一起有交流就算是结对编程,无所谓你们的目标是什么,至少你们的共同目标还是做好项目。
这样一来我们可以更容易的做一些改变,因为结对被打碎后变得更灵活了,尤其是对任务粒度粗而人数少的团队而言。
基于更细的粒度
现在,我们可以更容易的交换了,你只需要找到跟你目前做的部分有可能有重叠的其他人,或者更容易实践的做法是,找到可能跟你产生代码冲突的人,跟他结对去解决可能冲突的地方。可能是一个模块,也可能是一个方法,甚至是几行公用代码。
你肯定有个疑问,如果自己领的任务和其他人都没有关系怎么办。我想项目中总会有人擅长这个,或者做过类似的东西,找到他打断他目前的工作,和你一起搞定关键的部分,至少要让你明白如何做才能解决问题。如果没有这样的人,那说明也许你就是这个人,相信自己完成这个任务。或者可以找BA(业务分析师)一起结对完成,这样可以保证方向正确性。无论是什么情况,总会有办法找到你的结对对象,因为这是从你的意图出发找到的,它基于每个可能的冲突,而不是任务,所以你慢慢会发现,重要的是明确你的意图,找到方向,而不是和谁结对。
学会分解任务
要明确意图其实很容易,先弄清楚你的需求,也就是用户故事的内容,然后细分它们。但往往我们划分的任务最后看起来并不完全正确,大部分人并不明白分解任务是为了什么,按什么维度划分,要划分成多细的粒度,因为没有驱动力,只能完全凭借经验去分解任务。
现在当你一个人拿到一个用户故事后,你需要找一个结对的对象,所以你先得明确自己的任务意图,分解任务会变得很有动力。你需要考虑的是,分解出来的任务粒度是否和别人相近,否则你和其他人都会难以确定你们是否有冲突。这时你自然会明白需要具体到什么程度,以及包含哪些信息。
举个例子,你拿到的用户故事需要一个可编辑的列表,你首先肯定会考虑把它存到数据库。当你分解的任务粒度比较大时,可能是“保存A列表中的元素”,这样当另外一个人也需要操作另一个类似的B列表的时候,他可能不会想到你。而任务粒度太小,比如“创建数据库表xxx_a”,也是同样的情况。所以现在你分解任务时的问题会变成,如何更广泛的匹配其他人的任务呢?这样该任务也许会变成“通过数据库存储a,并显示到A列表中,它与b业务相关”。这不需要你写出来让别人看到,只要心中明白了这些任务就可以了,最重要的是认知。
迫切需要站会
刚刚你理解了自己的用户故事,但要找到你的结对对象,还需要了解其他团队成员的用户故事,或者当前正在做的任务。这时你会想到站会,是的,在敏捷中站会是最容易实现但最难实践的一环。说最容易是因为我们只要每天早上站一起就可以像模像样了,说最难是因为很难真的被利用到,因为这是一个全员的实践,需要每个人深刻的理解其意义。
我曾见过的最离谱的站会大致分为两种,一种是汇报式的,团队中层级最高的人会不自觉的站在中间,或者其他人会慢慢转向并围拢他,然后每个人向他报告自己昨天完成了什么,他们会忽略掉其他人,因为他们自己也没有向其他人讲述。另一种是结果式的,只说现在和某某正在结对,昨天完成了xx用户故事,或者正在做xx用户故事,明天准备做哪个xx用户故事,但没有任何细节和具体描述,这些信息其实看一眼物理墙就可以知道了。
然而现在不一样了,每个人心中都带着一个疑问,我昨天做的会不会影响其他人,今天准备做的会不会谁能帮到我。站会将不再难以捉摸,你会迫切的想表达自己之前做的,准备做的,遇到的问题,还有更重要的是对其他人的这三个方面异常的感兴趣,他们到底在做什么。
团队思维复杂度
渐渐的大家都会独立思考,不仅是思考自己做的事,还思考别人的事,因为除了你没有其他人会为了你的用户故事而思考。在一次简短的结对编程之后,你的结对对象只能确保你们之间没有冲突了,他所要的功能已经完成了,而你必须自己确保这个用户故事切实的完成了。这样,不会再有人所思考的东西是别人的子集,或者与其他人相似,每个人都有自己所要考虑的东西和目标,而其中又有许多交集。
这种看起来似乎是打乱团队一致性的效果,产生了一种很有趣的现象。不过在说清楚它的优劣之前,我必须先阐述清楚一个概念。团队中所有成员的思维之间有着许多相似和矛盾,这就是团队思维复杂度。
往往我们会不断增加团队的一致性,力求全员达成共识,这其实是在降低团队思维复杂度,这样不仅可以降低管理成本,还可以在有问题的时候及时调整,因为每个人得思想都是较为一致的,所以解决问题的能力较强,这叫做团队的恢复稳定性。但同时团队的思维和解决办法过于单一,容易陷入各种问题中,也就是所谓的一条腿走路的弊端。而如果团队过于复杂,每个人都有自己的想法,矛盾和制约无处不在,此时的团队很难被改变,却避免了前面所说的思维单一的问题,各种不同的思维会更大范围的覆盖各种解决方案,更多会去避免遇到问题,这是团队的规避稳定性。
也就是说当团队过于单一的时候,规避稳定性低,容易遇到问题,但恢复稳定性高,可以更好的解决问题。而复杂度较高的时候,规避稳定性高,可以提早发现并避免问题,但恢复稳定性低,一旦碰到严重问题,风险会非常大。所以在项目管理中,为了降低风险,我们应该找到一个更平衡的点去维持住团队思维复杂度,而不应该一味的增加或降低团队思维复杂度。
碎片化的结对编程恰恰是为了维持这一平衡的实践,在独立思考的团队中,每个人都将保有自己的思路,而结对的时候又会达到沟通思维的目的,使团队思维复杂度维持在一个中间水平。即能降低风险,又可以防止问题的发生。
广泛深入风险
说到风险,在敏捷中我们还提倡先做风险大的事,因为尽早发现问题暴露风险,才有更多的时间去消化风险解决问题。但往往我们很难识别风险,所以总会在低风险的用户故事中潜伏者一两个比较大的问题。
在我们的项目中总是会由相关技术的专家级成员来进行提前的分析,但一个人的精力是有限的,而且我们有时候很难判断一个用户故事所涉及的技术范围具体是什么,所以不如由做的人来提前分析。然而这样又产生了一个问题,在人员较少用户故事较多的团队中(比如我们团队),第一时间我们能接触到的用户故事是有限的,碎片化的结对编程可以很好的解决这个问题。当每个人都领取一个用户故事的时候,我们可以更大范围的接触到这个迭代的用户故事,尽早的找出或碰到有风险的问题,而且在实践中,我发现这些问题往往是和好几个用户故事相关的,如此一来,相当于多人分别识别风险,然后共同解决问题,开发效率和质量也会有一定提升。
驱动
在碎片化结对编程的实践中,我们也遇到过一些问题。比如当有几个用户故事是连续依赖的时候,我们还可以分别领取这些用户故事吗?即使分别领了卡,两个人还是会工作到被依赖的那个用户故事上。但你会发现这样其实并没有回到普通的结对编程状态,一个重要区别是,两个人仍然是抱有不同目标进行开发的。一个人的目标是完成这个用户故事,而另一个人的目标是让这个用户故事为其将要做的那个用户故事服务。所以做被依赖用户故事的人会被结对对象驱动。
有人会发现,这样不就是考虑太多了吗,用户故事不应该考虑以后的实现。其实这是一个平衡的过程,在成本相同的情况下,选择更好的方案肯定是没错的,关键在于不能将精力浪费在没用的东西上。而结对对象所关注的正是他挑的用户故事,他所关注的问题恰恰是除了当前的用户故事最应该被考虑的。在这种驱动和制衡下,你们会选择既能完成当前用户故事,又能让下一个依赖的用户故事更顺利的解决方案,避免一些风险。
总结
简而言之,碎片化的结对编程的主要思想是将一对结对对应一个用户故事的死板搭配更加合理的分散成多个结对对象对应多个特性的灵活搭配,以减少浪费。重要的是,每个人一定要形成自己独立的思维习惯,在这种实践下每个人都会自然而然的寻找自己的结对对象。
当然碎片化结对编程也有其局限,在人员对敏捷实践不熟悉的情况下,贸然使用很容易导致各自独立编程不结对的情况出现,它仅是对结对编程的一种适应性改进,适合于用户故事粒度较大,人员数量较少的团队。